《European Radiology》:Comparison of proprietary and fine-tuned large language models for multi-label classification of billing codes from radiology reports
编辑推荐:
为解决德国医疗计费系统自动化程度低、人工提取GO?码效率低下且易出错的问题,研究人员开展了一项研究,比较微调大型语言模型与商业、开源模型在放射学报告中自动分类GO?码的性能。研究发现,微调模型在保留测试集上取得了良好的准确率与F1值,并在真实世界样本中超越了表现最佳的商业LLM(如Gemini 2.5 Flash)。该研究表明,经过领域适应的轻量级模型能有效自动化计费流程,为提高医疗计费效率和准确性提供了可行方案。
在现代医疗系统中,准确高效的计费流程对于维持医院的财务稳定、确保服务获得合理报酬至关重要。在德国,针对私人医疗服务的计费遵循一项名为“德国医师收费条例”的标准,这一过程传统上高度依赖人工审核放射学报告,从中找出符合条件的服务并分配对应的收费代码。这项工作不仅耗时费力,还容易出现人为失误,可能导致计费不准确和收入损失。随着自然语言处理技术的飞速发展,特别是大型语言模型在医疗文本理解方面展现出的强大能力,人们不禁思考:能否利用这些“聪明”的模型来自动化处理这项繁琐的工作?本研究便以此为出发点,探索将大型语言模型应用于德国医疗计费码自动提取的可行性。
为此,研究人员开展了一项大规模研究,旨在评估经过微调的大型语言模型与先进商业及开源模型相比,在自动从放射学报告中分类德国医师收费条例代码方面的性能差异。研究得出的结论表明,经过领域特定数据微调的模型能够有效地自动化GO?代码的分类,并且在某些情况下,其性能甚至优于参数庞大的商业模型,这为在医疗环境中提高计费效率和准确性提供了一种有前景的、经济高效且注重数据隐私的本地部署方案。该研究已发表在《European Radiology》杂志上。
为了开展这项研究,研究人员主要采用了以下关键技术方法:首先是数据收集与处理,研究获伦理委员会批准后,从某大学医院的影像归档与通信系统中提取了来自124,497名患者的近50万份放射学报告,并使用Python及相关库(如pandas、sqlalchemy)进行数据检索和初步处理,报告仅进行解码,未应用复杂的文本归一化技术。其次是模型构建与训练,研究以已具备临床知识基础的MediPhi-Instruct 4B模型为基础,采用五折交叉验证进行微调,同时将通用大模型Ministral-3-8B-Instruct作为基准进行对比。最后是性能评估与对比,模型性能在保留测试集上进行了评估,并使用准确率、精确度、召回率和F1分数等指标进行衡量。此外,研究还从测试集中抽取了500份匿名报告和350份“清洁”报告样本,与GPT-5、GPT-4.1、DeepSeek-R1、Gemini 2.5等九种前沿大型语言模型进行零样本和少样本提示性能的横向对比。
结果
在验证数据集上的性能
经微调的模型在保留测试集上取得了77.15%±0.47%的准确率,微平均F1分数为87.79%±0.31%。集成模型的表现更佳,实现了85.54%±0.28%的准确率和88.62%±0.24%的微平均F1分数。模型在精确度(平均92.88%)上表现优于召回率(平均88.68%)。此外,经过医学领域预训练的MediPhi-Instruct在性能上持续优于通用基模型Ministral-3-8B。
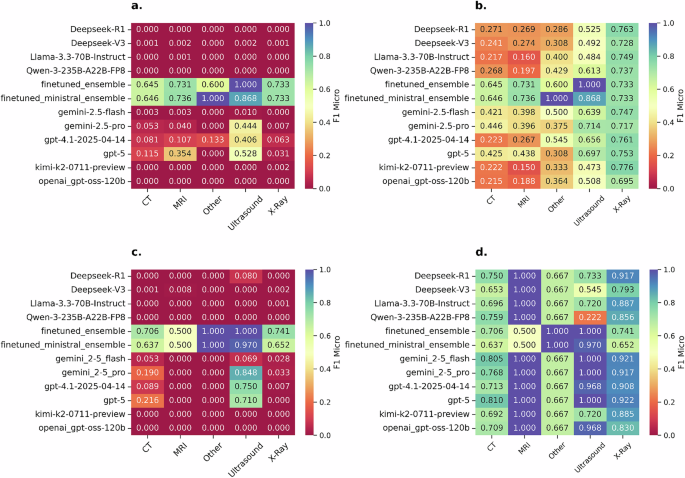
与大型语言模型的性能比较
真实世界数据集:在500份匿名报告样本上,微调集成模型的微平均F1分数(70.32%±1.54%)显著超越了表现最佳的大型语言模型Gemini-2.5-Flash(58.22%±1.50%),且统计差异显著(p<0.001)。
清洁数据集:在移除了特定机构附加费逻辑的350份报告样本上,GPT-5表现最佳,微平均F1分数达到89.51%±1.52%,并显著优于微调模型(p<0.001)。微调模型的F1分数为74.23%±1.41%,且精确度(64.84%)低于召回率(86.84%)。
按类别的性能表现
根据报告中描述的成像技术分类,不同模型的性能存在差异。对于真实世界样本,微调模型在各种成像技术(如X光、CT、MRI、超声)中表现最为一致。大型语言模型在超声类别的零样本任务中表现相对较好,而在X光类别上多数模型性能不佳。
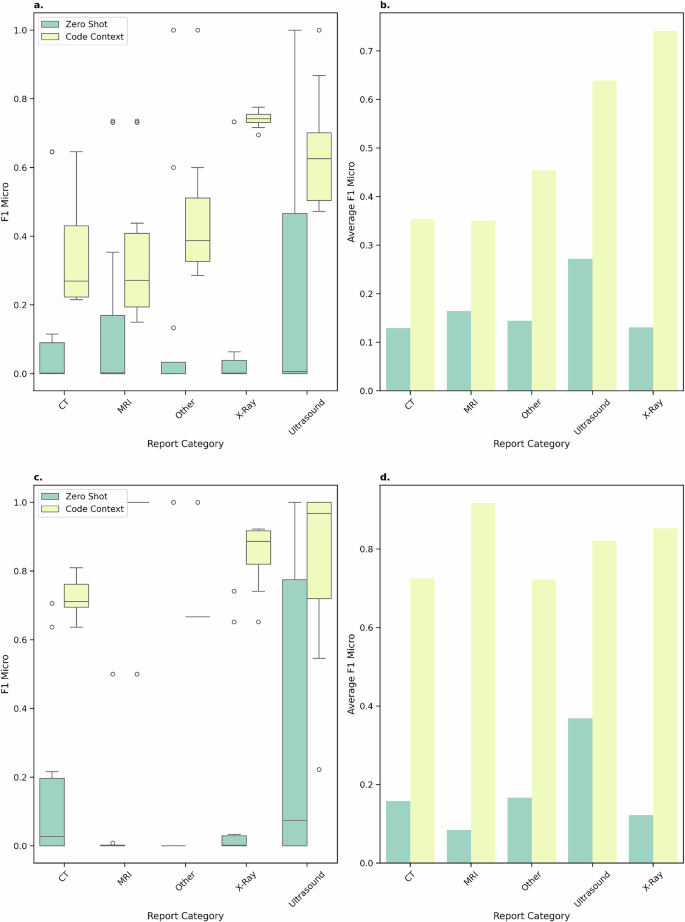
在少样本提示下,所有模型对X光和超声程序的分类性能较高且更稳定。
结论与讨论
本研究的结果表明,经过微调的先进大型语言模型能够有效地从非结构化放射学报告中预测计费代码。微调模型取得了具有竞争力的整体结果,尤其是在处理计费规则复杂性和医学术语混杂的挑战时。具体而言,经过领域适应训练的小型模型(MediPhi-Instruct 4B)在多数情况下优于参数更多的通用基模型(Ministral-3-8B),这凸显了在医学自然语言处理任务中,领域特定的预训练比单纯扩大模型规模更具价值。
研究发现,模型在完整验证集(F1 88.6%)与经过筛选的真实世界样本(F1 70.3%)之间存在性能差距,这反映了模型在自动化处理高频常规病例与理解复杂语义之间的区别。在更具挑战的真实世界子集上,微调集成模型显著超越了表现最好的少样本提示大模型(Gemini-2.5-Flash)。尽管GPT-5在简化后的“清洁”数据集上实现了更高的准确率(F1 89.5%),但微调模型在部署方面提供了一个更可行的折衷方案,因为它只需要最小的推理上下文,没有按令牌收费的API成本,并且可以在本地硬件上高效运行。
与现有研究的直接比较较为困难,因为据研究者所知,此前没有关于微调或评估大型语言模型进行德国医师收费条例代码分类任务的研究。不过,一些针对美国当前操作术语分类的研究表明,即使是经验丰富的医师编码员也可能在编码准确率上遇到挑战。本研究的结果为此类任务的自动化提供了有力证据。
微调方法的一个决定性优势在于数据主权。与需要外部数据传输的专有云模型不同,轻量级的MediPhi-Instruct模型可以本地部署,确保敏感的患者数据不离开医院防火墙,符合欧盟《通用数据保护条例》的要求。鉴于模型在罕见代码上的性能较低,“人在环路”的工作流程仍然至关重要。通过充当一个预筛选系统,为人工验证提供可能的代码建议,该模型可以显著减轻行政负担,并促进大规模的卫生经济学审计。
本研究也存在若干局限:依赖单中心回顾性数据可能引入机构特定的偏倚;作为基准事实的计费数据本身可能包含人为错误;对数据的匿名化和过滤改变了原始临床文本的结构;缺乏外部和前瞻性验证;以及大型语言模型部署本身存在的提示敏感性、幻觉等风险。
总而言之,这项研究证明了紧凑、经过微调的大型语言模型可以有效地自动化复杂的医疗计费任务,其性能水平有可能比肩甚至超越庞大的通用专有系统。研究结果挑战了“增大模型规模是提升临床自然语言处理性能的唯一途径”这一假设,并凸显了在高质量机构数据上进行领域特定适应训练的有效性。然而,考虑到生成式模型可能存在残余错误,此类工具目前应在“人在环路”的框架内实施,用于辅助而非取代专业的医疗控制人员。这项技术具有改变临床计费流程的潜力,但其使用应在合格专业人员的监督下进行。





 在少样本提示下,所有模型对X光和超声程序的分类性能较高且更稳定。
在少样本提示下,所有模型对X光和超声程序的分类性能较高且更稳定。

